

ChavrutAI’s Talmud Translation Processing Approach
With Appendix of Term Mapping Table Annotated With Discussions of Major Talmudic Technical Terms
When I began building the ChavrutAI digital Talmud reader, a core part of its intentionally opinionated value-add was the belief that merely presenting a translation is insufficient. The reader relies on ed. Steinsaltz’s English translation (by “translation”, I’m including the extensive additional in-line interpretations), accessed via Sefaria. This translation is a monumental accomplishment1 and, overall, remarkably accurate, but it also employs certain conventions that, in my view, create unnecessary barriers for contemporary readers and are at times less precise than they could be. This leaves room for improvement, or at least for a viable alternative that will better serve some audiences.
With that in mind, I developed a text-processing system that introduces a small number of carefully targeted interventions, subtly reshaping the translation into a form that I believe is both more accessible and more accurate.
Outline
Intro
The Challenge of Talmudic English
How the Processing Works
Terminology Modernization
Sexual terms
Ordinal Number Conversion
Structural Markers
Capitalization Consistency
Time and Calendar Terms
Hebrew Text Processing
Appendix 1 — Current Term Mapping Table (~40 Entries): Formatted, Hyperlinked, and Annotated With Discussions of Major Talmudic Technical Terms
Appendix 2 - Technical
Architecture
Term Replacement Implementation
Text Splitting Algorithm
Hebrew-Specific Processing
Performance Considerations
Extensibility
The Challenge of Talmudic English
Anyone who has read Talmud in English translation knows the experience: lengthy circumlocutions like “the Holy One, Blessed be He” can appear multiple times per page;2 archaic terms like “phylacteries” are used instead of the Hebrew words most learners already know; and euphemisms that use archaisms that make the text feel unnecessarily distant.
My goal was to make the text read more naturally without changing its meaning.
How the Processing Works
The system I built operates on several levels, each addressing a different aspect of readability.
Terminology Modernization
The most significant category of changes involves terminology. I created a mapping system that replaces certain terms with alternatives that are either more commonly used today or closer to the original Hebrew.
For example, ed. Steinsaltz’s archaic English translation “phylacteries” becomes the known transliteration “tefillin.” While “phylacteries” is the traditional English translation, anyone studying Talmud regularly (and also many casual, curious readers) will know the Hebrew term, and using the original term is worth it. Similarly, “ritual fringes” becomes “tzitzit“ and “ritual bath” becomes “mikveh.”3
Ed. Steinsaltz, to its credit, is quite consistent in its translations, making these programmatic conversions viable and accurate.
Religious circumlocutions are simplified. “The Holy One, Blessed be He” and its variants become simply “God.”4 “The Divine Presence” becomes “Shekhina.” “The Divine Voice” becomes “bat kol.” These changes reduce visual clutter while actually bringing readers closer to the original Hebrew terminology.5
Sexual terms
The system also handles euphemistic language. Ed. Steinsaltz, like many translations (especially traditional ones, and older ones) often employ elaborate phrases like “engage in conjugal relations” where the original text is quite direct.6 My processing simplifies these to plain language that matches the tone of the original.7
Ordinal Number Conversion
A small but noticeable change: the system converts written-out ordinal numbers (=words representing position or rank in a sequential order, e.g. first, second, etc) to their numeric form. “The twenty-first of Nisan” becomes “the 21st of Nisan.”
This reduces visual density, particularly in passages dealing with dates or measurements, which appear frequently in halakhic discussions.8
Structural Markers
The translations I work with use labels like “GEMARA” and “MISHNA” to indicate structural divisions in the text. My system converts “GEMARA” to “Talmud” and ensures “MISHNA” remains properly formatted.9
Capitalization Consistency
Certain terms benefit from consistent capitalization to indicate they refer to specific historical or theological concepts. “The flood” when referring to the biblical Flood becomes “the Flood.” “Generation of the flood” becomes “Generation of the Flood.”
These changes help readers recognize when the text is referring to well-known biblical events rather than generic descriptions.
Time and Calendar Terms
For accessibility, certain Jewish calendar terms are converted to their common equivalents when the context is clear. The archaic “Shabbat eve” and “the eve of Shabbat”, which translate the Hebrew erev Shabbat (ערב שבת) become “Friday,” since this is what the term means and using it helps readers immediately understand the temporal context.
Hebrew Text Processing
The system also processes the Hebrew text that appears alongside the English translation. Here the goals are different: I remove nikud (vowel points) to present the text as it traditionally appears in printed editions of the Talmud,10 and I apply consistent paragraph breaks based on punctuation patterns.11
Appendix 1 — Current Term Mapping Table (~40 Entries): Formatted, Hyperlinked, and Annotated With Discussions of Major Talmudic Technical Terms
Based on the current mapping table, the relevant code can be seen in context here. Minor variants have been omitted; for example, differences in plural form, capitalization, and trailing punctuation. I’ve also added formatting (italics), hyperlinks, annotations, where relevant.
“Gemara”: “Talmud”,
“Rabbi”: “R’”,
“The Sages taught”: “A baraita states”,12
“Divine Voice”: “bat kol”,
“Divine Presence”: “Shekhina”,
“divine inspiration”: “Holy Spirit”,13
“Divine Spirit”: “Holy Spirit”,
“the Lord”: “YHWH”,14
“leper”: “metzora”,
“phylacteries”: “tefillin”,
“gentile”: “non-Jew”,16
“ignoramus”: “am ha’aretz”,17
“maidservant”: “female slave”,18
“barrel”: “jug”,19
“the Holy One, Blessed be He“: “God“,
“the Merciful One”: “God”,20
“the Almighty”: “God”,
“the Omnipresent”: “God”,
“Master of the Universe,”: “God!”,
“Master of the World”: “God!”,
“sky-blue”: “tekhelet”,
“ritual fringes”: “tzitzit”,
“ritual bath”: “mikveh”,
“malicious speech”: “lashon hara”,
“bloodshed”: “murder”,21
“nations of the world”: “non-Jewish nations”,22
“mishna”: “Mishnah”,
“harlot”: “prostitute”,23
“rainy season”: “winter”,24
“eye shadow”: “kohl”,25
“the flood”: “the Flood”,26
“generation of the flood”: “Generation of the Flood”,
“generation of the dispersion”: “Generation of the Dispersion”,27
“Shabbat eve”: “Friday”,
Appendix 2 - Technical
This appendix describes the technical implementation details of the text processing system.
Architecture
The text processing logic is implemented in TypeScript and runs on both server and client. The core module (shared/text-processing.ts) exports pure functions that take text strings and return processed versions. This design allows the same processing logic to be used during API responses on the server and for real-time processing in the browser.
Term Replacement Implementation
Term replacements are implemented using a dictionary-based approach. A Record<string, string> object maps source terms to their replacements. The replacement function iterates through this dictionary and applies regex-based substitution with word boundary matching (\b) to avoid partial matches.
For complex term families, I use programmatic generation. The sexual terminology mappings, for instance, are generated by combining a list of base terms with a list of verb conjugations, producing all valid combinations without manual enumeration.
Ordinal numbers are processed in two passes: compound ordinals (like “twenty-first”) are processed before basic ordinals (like “third”) to prevent incorrect partial matching.
Text Splitting Algorithm
Both Hebrew and English text undergo structural splitting to improve readability. The algorithm:
Protects HTML tags by replacing them with placeholders before processing
Identifies punctuation marks that indicate logical breaks
Inserts line breaks after these marks
Restores HTML tags from placeholders
Cleans up redundant whitespace
For English text, additional logic handles quotation marks adjacent to punctuation (e.g., .” or ?’) as single units to avoid splitting in the middle of quoted speech. The system also protects genealogical attributions like “X, son of Y, said” from being split, as these are common patterns in Talmudic discourse.
Hebrew-Specific Processing
Hebrew processing includes nikud removal using Unicode range matching. The regex pattern [\u0591-\u05AF\u05B0-\u05BD\u05BF\u05C1-\u05C2\u05C4-\u05C5\u05C7] matches all Hebrew vowel points and cantillation marks.28
Mishnah and Gemara markers (מתני׳ and גמ׳) receive special handling to ensure line breaks appear after them regardless of surrounding HTML formatting.
All this is addition to the key fact that it is open-access, and easily accessible via Sefaria’s API.
Note that in traditional rabbinic writing this term is almost always abbreviated as an acronym (הקב״ה - i.e. ‘HKB”H’); see the later note on this term.
Note that Wikipedia follows the same practice: its article titles generally use transliteration (tefillin, tzitzit, mikveh) rather than archaic translated forms (phylacteries, ritual fringes, ritual bath). Of course, a factor in that case is likely the need to distinguish these terms from their broader, general usage, outside of a Jewish context.
For a general discussion, see my “The Many Names of God: Divine Epithets in the Talmud”, section “Ha-Kadosh Barukh Hu (הקדוש ברוך הוא) – “The Holy One, Blessed be He” ”, where I write:
This is arguably the most iconic rabbinic epithet for God.
Composed of two adjectives—kadosh (holy) and barukh (blessed)—it emerged prominently in the Tannaitic and early Amoraic periods. It is often abbreviated in rabbinic writing as הקב״ה.
This is just a representative sample of the mappings; the full, up-to-date list appears in “Appendix 1 — “Current mapping table of terms (~40 mappings)” at the end of this piece, where additional formatting (italics), hyperlinks, and annotations are provided where relevant.
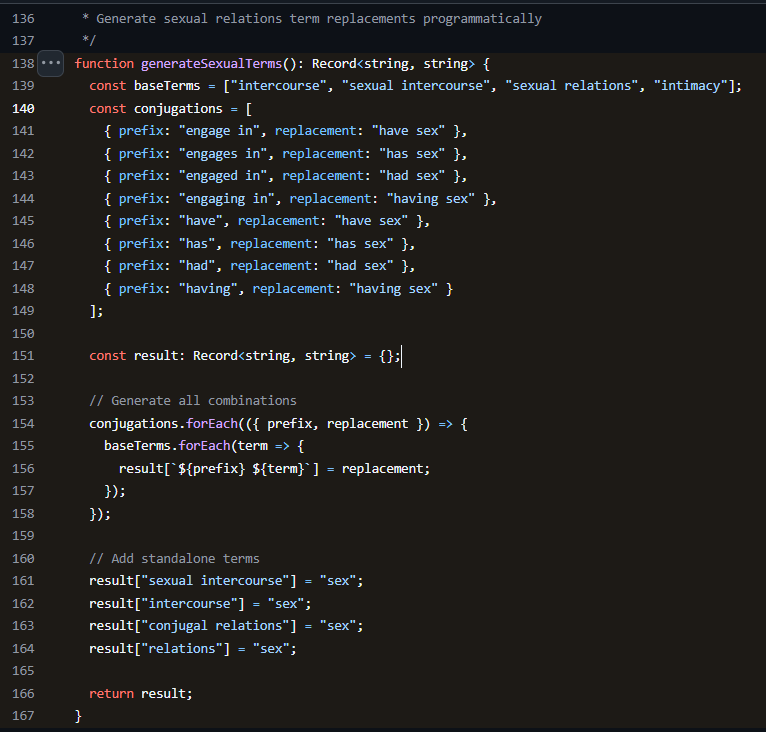
Compare my general related discussion in “[Appendix 3 - Hebrew Verbs for “Sex”]”.
The specific terms processed: “intercourse”, “sexual intercourse”, “sexual relations”, “conjugal relations”, “intimacy”, are all processed as “sex”.
See the full code snippet here. The code accounts for the many verbal permutations (“engages, has”, etc). Screenshot:
Compare my general related discussion in “Large Numbers (≥100) in the Talmud: A Data Analysis”.
On the term “Talmud” vs. the term “Gemara”, see my general related discussion in “Beyond the Mystique: Correcting Common Misconceptions About the Talmud, and Pathways to Accessibility”, section “Myth #3: The Talmud is Divided into Two Parts - Mishnah and Gemara”.
See my general discussion of this in “Symbols and Syntax: Punctuation and Nikud in the Talmud”.
See a bit more detail about this in the technical appendix at the end of this piece, section “Text Splitting Algorithm“ and “Hebrew-Specific Processing”.
Translating tanu rabbanan (תנו רבנן).
On this technical term, see these pieces of mine:
“Rabbis Incognito: Generic, Anonymous, and Group Referents in the Talmud“, section “Rabbanan (רבנן) - Rabbis“
“Signposts in Sacred Text: Formulaic Terms Used in Talmud Bavli“, section “Commonly used formulaic terms in the Talmud Bavli, divided by type“
Here, in “Appendix 2: Formulas for Introducing Stories in the Bible and Talmudic Literature“
Translating ru’ah ha-kodesh (רוח הקודש).
Translating the Tetragrammaton (God’s standard 4-letter name), as it appears in the Bible.
On this term, see these pieces of mine:
“The Many Names of God: Divine Epithets in the Talmud“ (cited earlier), section “YHWH (יהוה) - “the Lord”“.
“Talmudic Justifications for Biblical Stories that Contradict Halacha: Hora’at Sha’ah and Et La’asot - Pt. 1”, section “Saying God’s explicit name (שם המפורש - the 4-letter name ‘YHWH’)“.
Note that “leprosy” is an incorrect and misleading translation for tzara’at, as is well-known. In fact, tzara’at is a biblical term for a category of skin diseases, with nowhere close to a one-to-one English translation.
In this regard in general—biblical and Talmudic terms for a category with nowhere close to a one-to-one English translation—compare these terms:
sheretz - שרץ - translated by ed. Steinsaltz as “a creeping animal”. See my note here.
behemah dakkah / gassa - בהמה דקה / גסה - translated by ed. Steinsaltz as “small / large domesticated animals”. These terms refer to sheep/goats and cows, respectively. Compare my note on “Labor, Lamps, and Livestock: Local Norms, Pluralism, and Halachic Variance by Time and Place (Mishnah Pesachim 4:1-5)“, section “3 - Local Customs and Restrictions on Selling Livestock to Non-Jews“, and appendix there: “Appendix 2 - Restrictions on raising animals in Eretz Yisrael, especially sheep and goats (Mishnah Bava Kamma 7:7; Talmud Bavli, Bava Kamma 79b)“.
See my discussion of this term in the intro to “Pt1 Rabbinic Elitism and the Am Ha’aretz: Hierarchy, Hostility, Hatred, and Distrust (Pesachim 49b)“.
Translating the Hebrew shifha (שפחה), or the Aramaic amta (אמתא - cognate with Hebrew amah - אמה).
Often translating Hebrew havit (חבית). See my discussion of this and related terms for wine containers in an extended footnote on “Pt1 Permissibility of Jewish Wine in the Hands of Non-Jews: Ten Talmudic Cases Explored (Avodah Zarah 69b-70b)“, section “Story: Non-Jew Enters House with Jewish Wine, Locks Door, but Visible Through Crack“.
On this term for God, and the following ones, see my discussion in “The Many Names of God: Divine Epithets in the Talmud“ (cited earlier).
Translating shefikhut damim (שפיכות דמים).
Translating umot ha-olam (אומות העולם).
Translating zonah (זונה).
Translating yemot ha-geshamim (ימות הגשמים).
Translating mabul (מבול).
Translating dor ha-palagah (דור הפלגה), the standard Talmudic term for the generation of the biblical Tower of Babel.
For more on this, see my “How to Programatically Strip Hebrew Nikud from a Hebrew Text“.