

Introducing a New Talmudic Glossary
Mapping Talmudic Names and Technical Terms
I built a new public glossary page for my Talmud NLP project, and I want to explain what it is, why I made it, and how to use it.
If you study classical Jewish texts, you already know the recurring problem: names, places, and technical concepts show up constantly, often in variant forms, and often without context. You may recognize a term, but not remember whether it is a person, a place, a biblical reference, or a legal concept. You may remember hearing a name in one tractate and then seeing a slightly different version somewhere else.
I wanted a practical tool for this; a working glossary that helps with real reading.
The result is this page:1
https://ezrabrand.github.io/talmud-nlp-indexer/glossary/
Outline
Intro
What this page does
Why I built it this way
Screenshots
Entries = “concepts” (filtered for that tag)
Entries = “[talmudic] names” (filtered for that tag)
Entries = “biblical names” (filtered for that tag)
Entries = “talmud toponyms” (filtered for that tag)
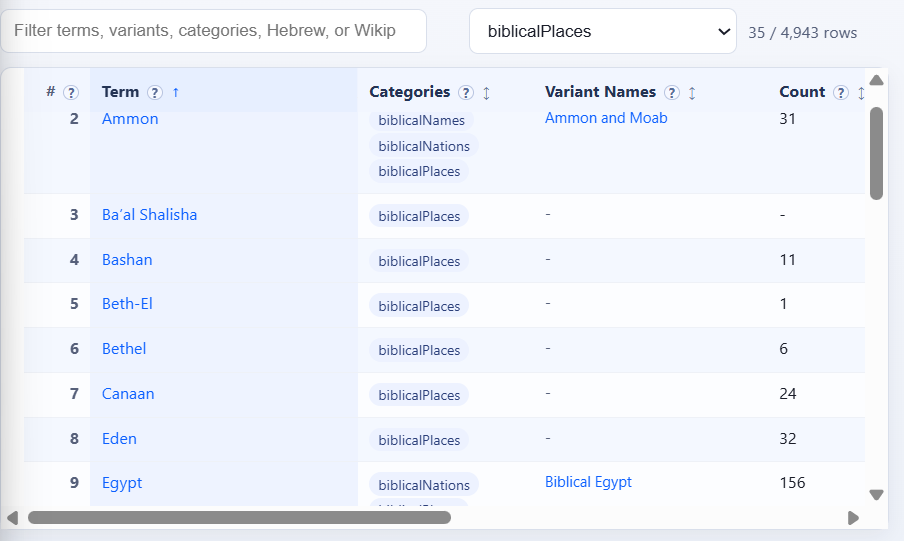
Entries = “biblical places” (filtered for that tag)
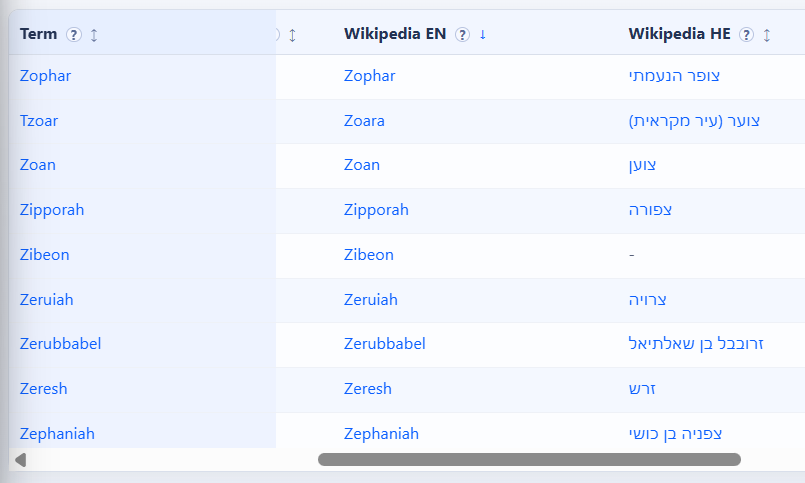
Entries with corresponding English Wikipedia entries (sorted for that col)
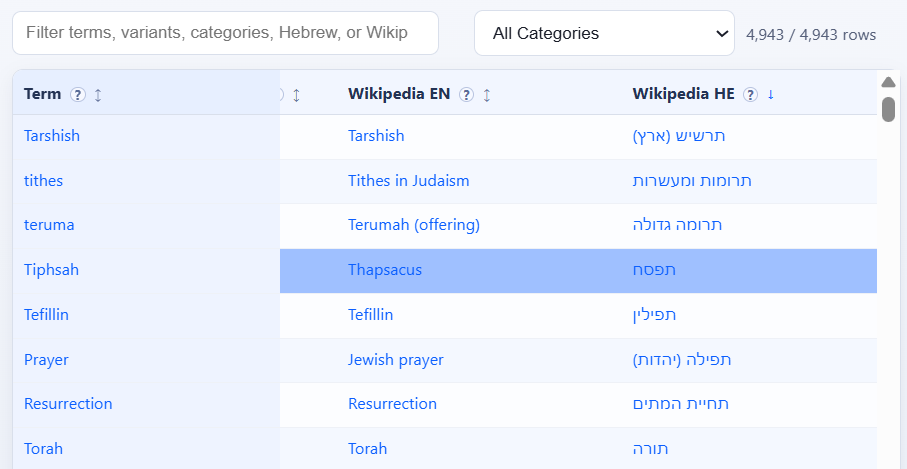
Entries with corresponding Hebrew Wikipedia entries (sorted for that col)
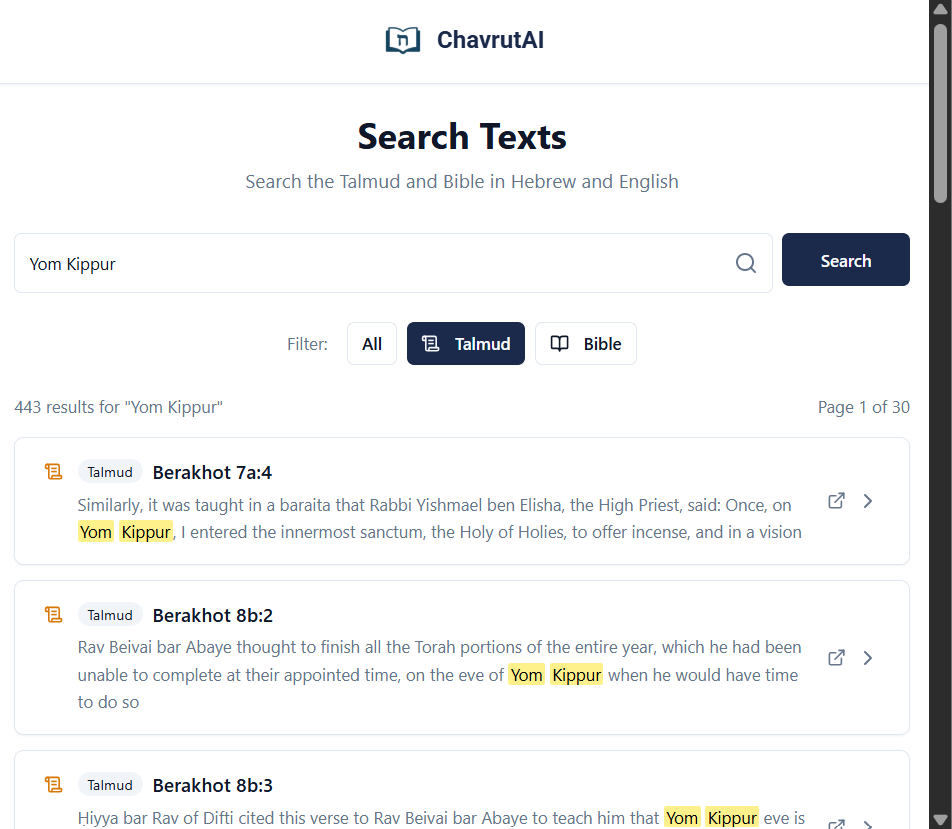
Clicking on hyperlink to open query in ChavrutAI search (eg. term = “Yom Kippur”)
What is still imperfect
What readers can do with it now
The bigger project context
Why this matters for classical text study
What comes next
Appendix - Technical
Data sources
Canonicalization and variants
Count column
Hebrew link enrichment
GitHub Pages interface
What this page does
The glossary page ties together a number of projects that I’ve been working on. It presents a large table of terms that I assembled from multiple gazetteers and then enriched.
Each row is a canonical entry, and each entry includes:
a term name
category labels
variant names
a corpus count (how often it appears in the English Talmud corpus)
English and Hebrew Wikipedia links when available
Hebrew label when available
I added direct links from terms and variants into ChavrutAI search so you can jump from reference data into text exploration immediately.
Why I built it this way
I used existing structured resources from my Talmud NLP Indexer work, especially the gazetteers that already power term highlighting in ChavrutAI.
Then I did the following:
deduping obvious duplicates, consolidating variants under a canonical entry
mapping to Wikipedia (English and Hebrew)
counting term frequency in the Talmud corpus
building a browsable page
Screenshots
Entries = “concepts” (filtered for that tag):
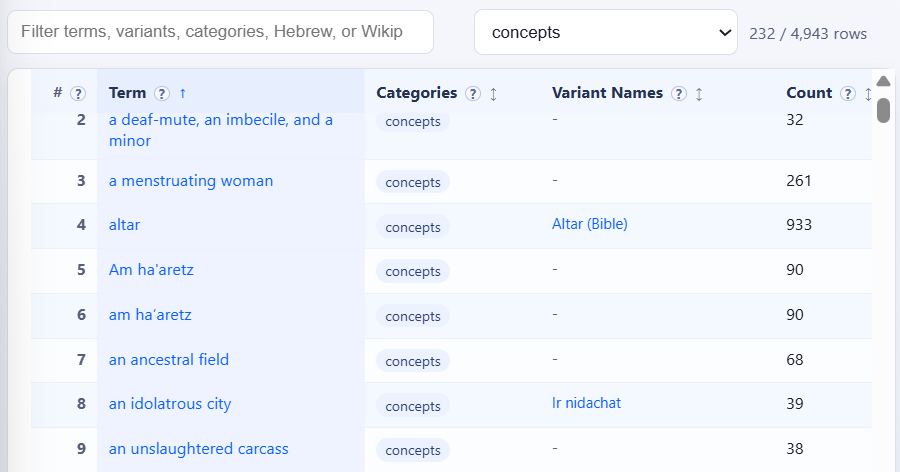
Entries = “[Talmudic] names” (filtered for that tag):
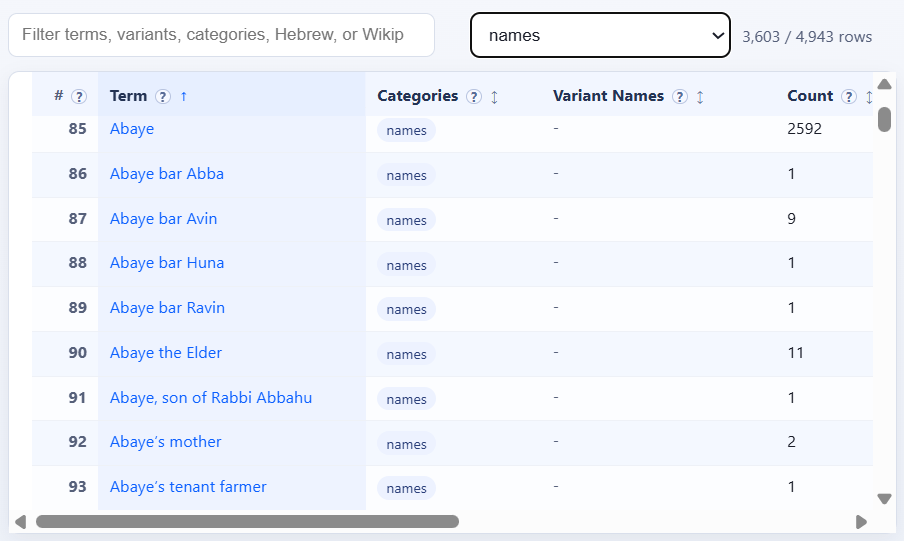
Entries = “Biblical names” (filtered for that tag):
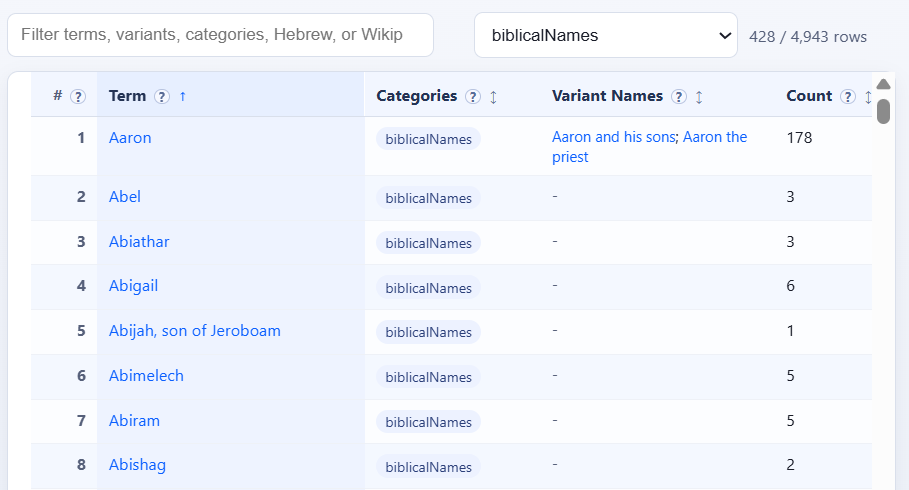
Entries = “Talmud toponyms” (filtered for that tag):
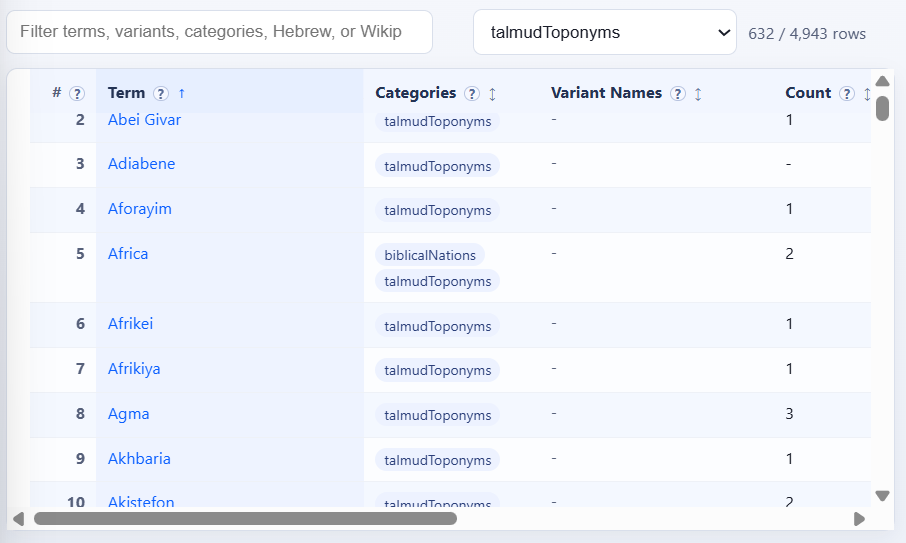
Entries = “Biblical places” (filtered for that tag):
Entries with corresponding English Wikipedia entries (sorted for that col):
Entries with corresponding Hebrew Wikipedia entries (sorted for that col):
Clicking on hyperlink to open query in ChavrutAI search (eg. term = “Yom Kippur”):
https://chavrutai.com/search?q=Yom%20Kippur:
What is still imperfect
This is very useful (in my humble opinion!), but it is not finished.
Some entries still need manual curation, some are incomplete, some names are tricky because transliteration is inconsistent across sources. Hebrew mappings are much better now, but some English pages still have no straightforward Hebrew link in the API workflow.
What readers can do with it now
Even in this initial form, the page is already practical for actual use:
Filter by category to narrow the scope quickly.
Sort by count to see high-frequency terms first.
Open a term or a variant in ChavrutAI search and move into actual passages.
Use Wikipedia links to get quick orientation when needed.
The bigger project context
This glossary is one part of a broader project:
structured extraction of terms from rabbinic corpora
alignment between named entities, concepts, and places
practical interfaces for non-specialist readers
I care about this because the barrier to entry in these texts is often lack of background navigational tools.2
Why this matters for classical text study
Classical Jewish texts are dense, layered, and strongly intertextual. By surfacing variants and cross-links in one place, it’s much easier to situate oneself.
What comes next
Near-term improvements I plan:
better manual curation on unresolved Wikipedia mappings
stronger alias handling for transliteration edge cases
adding Sefaria mappings where appropriate
Long-term, I plan on incorporating this directly into the ChavrutAI website itself.
Appendix - Technical
This section summarizes the implementation choices.
Data sources
Primary source files are in this repo, in these txt files:
data/talmud_concepts_gazetteer.txtdata/talmud_names_gazetteer.txtdata/bible_names_gazetteer.txtdata/nations_and_demonyms_gazetteer.txtdata/bible_places_gazetteer.txtdata/talmud_toponyms_gazetteer.txt
Additional enrichment sources:
extracted Wikipedia links from blog HTML files
curated links from
comparative_topic_tree_hyperlinked.html3EN->HE Wikipedia
langlinksvia MediaWiki API4
Canonicalization and variants
Rows were deduped into canonical entities, preferring canonical names from Wikipedia EN when available. Variant forms were merged into variant_names.
I also corrected edge cases where a Hebrew-script term became canonical due to missing EN mapping; canonical term display is now kept in English where possible.
Count column
talmud_corpus_count is computed from data/talmud_full_english.txt5 using tokenized phrase matching.
Counting includes:
canonical term
all listed variants
Normalization includes:
transliteration diacritic folding (for example dotted letters)
apostrophe normalization across Unicode variants
Script used: data/glossary_initial/update_corpus_counts.py
Hebrew link enrichment
Script: data/glossary_initial/enrich_he_from_en_langlinks.py
Method:
query EN Wikipedia API in batches for Hebrew
langlinksresolve normalized/redirect titles
fill
wikipedia_heandhebrew_termwhen availableexport unresolved rows for manual review:
data/glossary_initial/missing_he_wiki_after_langlinks.csv
GitHub Pages interface
Published from docs/
Main page: docs/glossary/index.html
Features implemented:
text filter + category filter
sortable columns (including numeric sort for Count)
row numbering and row highlighting
term and variant links into ChavrutAI search
responsive table styling
Note that this is a work-in-progress, as I discuss later.
The Github repo with the underlying data and scripts is here: https://github.com/EzraBrand/talmud-nlp-indexer/tree/main/data/glossary_initial.
Note that in the current state of this table/database, it's closer to an index than to a glossary. But I called it a glossary because I plan to continue to iterate on it, and develop into something that's indeed closer to a glossary. In addition, I've worked on a few unrelated projects that are indeed purely indexes (Talmud-Bible; Talmud-Mishnah; and others), so calling it an index might lead to unnecessary confusion.
See especially my previous discussion in “Beyond the Mystique: Correcting Common Misconceptions About the Talmud, and Pathways to Accessibility“.
On that specific file, see my recent piece: “Introducing a High-Level Mapping of Jewish Law, by Major Topic: Bible, Mishnah, Mishneh Torah, and Shulchan Aruch“.
For more on this, see Wikipedia, “Help: Interlanguage links“. These links are found at the top of right of any Wikipedia entry with a corresponding page in another language’s Wikipedia.
Screenshot of the relevant part of the page just mentioned, for example:
This is the Steinsaltz translation of Talmud (from Sefaria), excluding non-bolded interpretation and Bible verse quotations. I’ve used this corpus on several occasions and have referred to it in earlier discussions.