

Mapping the Talmud: Scalable Natural Language Processing (NLP) for Named Entities, Topics, and Tags in the Talmudic Corpus
Using NLP to Index, Parse, and Annotate the Talmud
This is an overview of an ongoing project that ties together a number of ideas that I’ve been developing.1
Intro
The Babylonian Talmud stands as the cornerstone of Rabbinic literature. Spanning thousands of pages, its intricate dialogues, legal debates, ethical teachings, and narrative passages have captivated and challenged readers for centuries.
However, the sheer volume of the Talmud2 presents significant hurdles for comprehensive study and large-scale analysis. How can we use modern technology to navigate this vast sea of text and uncover new layers of meaning?
This post introduces the "Talmud NLP Indexer," a project exploring the application of Natural Language Processing (NLP) - a field of computer science focused on enabling computers to understand human language - to the text of the Babylonian Talmud.
Our goal is to develop computational tools that can automatically analyze, index, and tag the Talmud page by page, potentially opening up new avenues for research and understanding.
Outline
Intro
The Challenge of Talmudic Text
Project Overview & Data Source
Processing the Text: A Bilingual Approach
Tagging the Talmud: People and Places
Tagging the Talmud: Concepts and Topics
Current Status and Achievements
Gazetteers
Talmud names Gazetteer
Talmud place names (=toponyms) Gazetteer
Talmud concepts Gazetteer
Bible names Gazetteer
Bible place Gazetteer
Bible nations Gazetteer
An Example, With Screenshots: Berakhot 7a
Screenshot - first lines of a total of 800+ lines - Bilingual text, and recognized named ‘entities’:
Example from Berakhot 3a
Screenshot of whole ‘sentences’ extracted (text processed to include only bolded, which is the direct translation in ed. Steinsaltz, as opposed to gloss/ commentary/ interpretation):
Screenshot of ‘tags’, human-readable:
Screenshot of ‘noun phrases’:
Example of identified ‘Bolded & Italicized Words’
Future Directions and Potential Applications
Conclusion
Appendix - Blog Archive and Tagging on GitHub Repo
The Challenge of Talmudic Text
Studying the Talmud is challenging,3 and computational methods offer exciting possibilities. By treating the text as data, we can begin to analyze it at a scale and with a consistency that complements traditional scholarship.
Project Overview & Data Source
The "Talmud NLP Indexer" project aims to build a system that programmatically reads and analyzes the Talmud. At its core, the project leverages the rich digital resources available today, specifically the extensive library provided by Sefaria.
Sefaria offers free access to a vast collection of Jewish texts, including the full Babylonian Talmud in its original Hebrew/Aramaic,4 as well as an excellent and reputable English translation (ed. Steinsaltz).
Our system utilizes Sefaria's API to automatically retrieve the text of the Talmud, page by page. Accessing both the original language and the English translation is key, allowing our system to perform different types of analysis suited to each language's characteristics.
Processing the Text: A Bilingual Approach
Once the text for a page is retrieved, the system begins its analysis. Recognizing the distinct linguistic features of the original text and its translation, we employ a bilingual processing strategy.
For the English translation, the system focuses on identifying recognizable elements. It reads the text to pinpoint mentions of people (like "Rabbi Akiva"), places ("Babylonia"), concepts, numbers,5 and other specific entities.
It also identifies core noun phrases, which often represent key subjects being discussed.
For the original Hebrew and Aramaic text, the system uses different, more language-specific techniques.
These advanced methods allow it to capture deeper linguistic patterns and relationships between words, providing a complementary layer of analysis that goes beyond simple keyword spotting. This dual approach aims to harness the strengths of analyzing both the translation and the original language.
Tagging the Talmud: People and Places
A key output of the system is a set of descriptive "tags" for each page, similar to index keywords. These tags help categorize the content and make it more searchable. A major focus is identifying the "who" and "where."
The system is trained to recognize mentions of individuals – the Sages of the Talmud (Tannaim and Amoraim) as well as figures from the Bible.
To improve accuracy, it cross-references potential names against curated lists, known as "gazetteers," containing thousands of known names from the Talmudic and Biblical periods.6
This helps distinguish, for example, between different Rabbis with similar names and ensures figures like "Moses" or "King David" are correctly identified.
Similarly, the system identifies geographical locations mentioned, from cities and regions within Talmudic Babylonia and Roman Eretz Yisrael (like Pumbedita or Caesarea, respectively) to significant biblical sites (like Jerusalem or Mount Sinai).
Again, gazetteers specific to Talmudic and Biblical geography are used to verify these place tags. The system also differentiates between general locations and those specifically from the biblical context.
Tagging the Talmud: Concepts and Topics
Beyond concrete names and places, the Talmud is rich with abstract concepts and recurring themes. Our system also attempts to tag these.
Using another set of curated lists, the system identifies mentions of key Jewish or Talmudic concepts, such as "Shabbat," "Prayer," "Tefillin," "Mercy," "Divine Presence."
Tagging these concepts allows researchers to easily find discussions related to specific theological or legal ideas across different tractates.
Furthermore, the system employs techniques to identify the broader subjects or themes being discussed on a page, even if specific keywords aren't used.
By analyzing word patterns and co-occurrences, it tries to generate "topic" tags that represent the main focus of the discourse (e.g., a discussion primarily revolving around "blessings" or "laws of damages"). This helps provide a higher-level overview of the page's content.
Current Status and Achievements
The Talmud NLP Indexer is an ongoing project, currently focused on the initial tractate, Berakhot.
The foundational pipeline is functional: the system can automatically fetch text from Sefaria, perform bilingual processing using established NLP tools and models adapted for Hebrew/Aramaic, generate tags based on entity recognition, keyword matching, extensive gazetteer lookups (for people, places, concepts, including biblical distinctions), and basic topic analysis.
Gazetteers
Talmud names Gazetteer
https://github.com/EzraBrand/talmud-nlp-indexer/blob/main/data/talmud_names_gazetteer.txt
Screenshot (20 lines of 3200+ lines, extracted by me previously from ed. Steinsaltz, cited also earlier: Talmud Personal Names Extracted From Steinzaltz Translation):

Talmud place names (=toponyms) Gazetteer
https://github.com/EzraBrand/talmud-nlp-indexer/blob/main/data/talmud_toponyms_gazetteer.txt
Screenshot (first 20 lines of 280+ lines, extracted by me previously from ed. Steinsaltz, cited also earlier: Talmud Geographical Names (Toponyms) Extracted From Steinzaltz Translation):

Talmud concepts Gazetteer
https://github.com/EzraBrand/talmud-nlp-indexer/blob/main/data/talmud_concepts_gazetteer.txt
Screenshot (first 20 lines of 280+ lines, programmatically extracted by me from hyperlinked words in my last 2 years of blogposts - ~400 blogposts):

Bible names Gazetteer
https://github.com/EzraBrand/talmud-nlp-indexer/blob/main/data/bible_names_gazetteer.txt
Screenshot (first 20 lines of 1300+ lines, extracted from relevant Wikipedia entries and categories):

Bible place Gazetteer
https://github.com/EzraBrand/talmud-nlp-indexer/blob/main/data/bible_places_gazetteer.txt
Screenshot (first 20 lines of 400+ lines, extracted from relevant Wikipedia entries and categories):

Bible nations Gazetteer
https://github.com/EzraBrand/talmud-nlp-indexer/blob/main/data/bible_nations_gazetteer.txt
Screenshot (first 20 lines of 50+ lines, extracted from relevant Wikipedia entries and categories):

An Example, With Screenshots: Berakhot 7a
Let's consider page 7a of Tractate Berakhot as an example:
https://github.com/EzraBrand/talmud-nlp-indexer/blob/main/data/Berakhot_7a.json
When processing this page, the Talmud NLP Indexer generates a variety of tags:
People: It identifies numerous figures, including Talmudic sages like
Rabbi Yochanan, Rabbi Yehoshua ben Levi, Rabbi Shimon ben Lakish(tagged asperson:). It also identifies biblical figures likeMosesandBalaam, tagging them specifically (e.g.,person:bible:moses).Places: It tags locations like Israel (
place:bible:israel).Concepts: Following recent updates, it now tags discussions involving key concepts mentioned on this page, such as
concept:anger, concept:mercy, concept:prayer.Topics: Based on keyword analysis, it might add tags like
topic:prayerif terms related to prayer are prominent.
This combination of tags provides a multi-faceted snapshot of the page's content, highlighting the key figures, locations, concepts, and potential topics discussed.
Screenshot - first lines of a total of 800+ lines - Bilingual text, and recognized named ‘entities’:
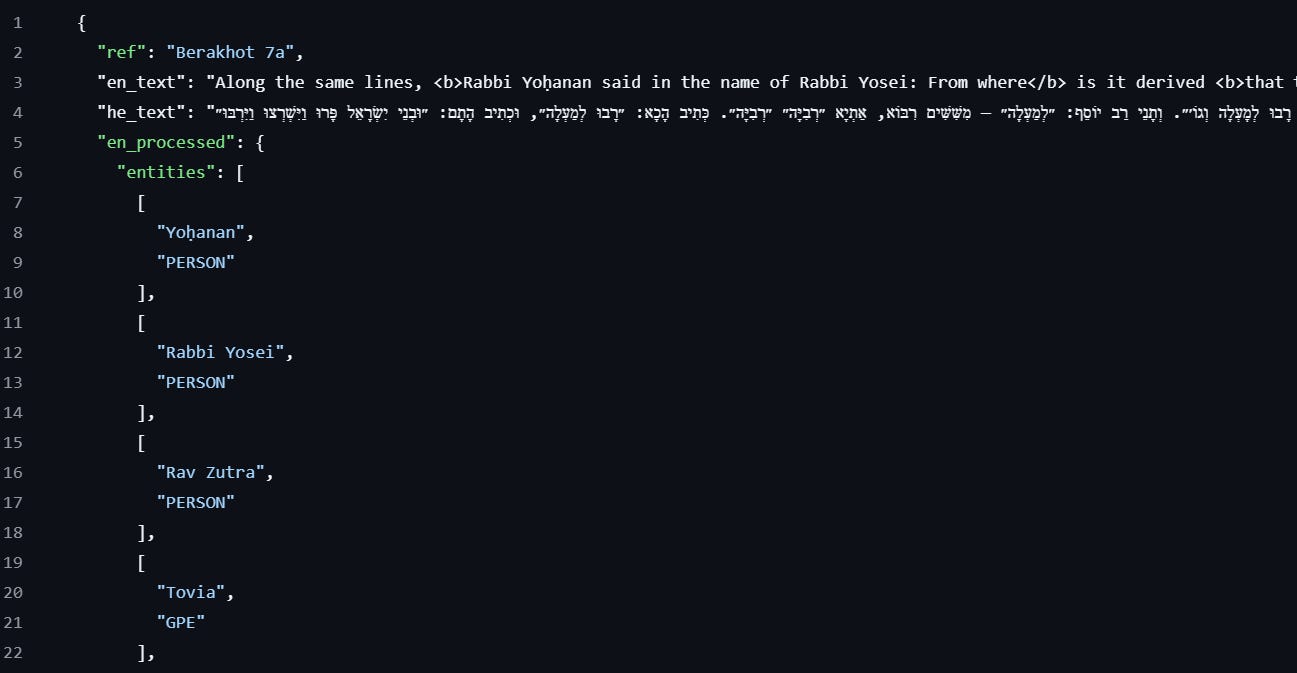
The results for each processed page, including the original texts, the structured analysis, and the generated tags, are saved in an accessible format (JSON files).
Example from Berakhot 3a
Link (url) to the JSON output:
https://github.com/EzraBrand/talmud-nlp-indexer/blob/main/data/Berakhot_3a.json
Screenshot of whole ‘sentences’ extracted (text processed to include only bolded, which is the direct translation in ed. Steinsaltz, as opposed to gloss/ commentary/ interpretation):
In the human-readable file (=Markdown):7
https://github.com/EzraBrand/talmud-nlp-indexer/blob/main/data/Berakhot_3a.md:

Screenshot of ‘tags’, human-readable:

Screenshot of ‘noun phrases’:

This allows the processed data to be easily reviewed, shared, and potentially integrated into other digital tools or research workflows.
We have also established a testing framework to help ensure the reliability of the different components as the project evolves.
Example of identified ‘Bolded & Italicized Words’
https://github.com/EzraBrand/talmud-nlp-indexer/blob/main/data/Berakhot_4a.md

Future Directions and Potential Applications
While the initial results are promising, there is much more to explore.
Our immediate next steps include refining the tagging accuracy (for instance, ensuring personal names are not occasionally misidentified as places), expanding the system's coverage beyond the first few pages of Berakhot to encompass more of the Talmud, and enhancing the analysis of the Hebrew/Aramaic text.
We also plan to improve how the system identifies broader topics and make its configuration more flexible.8
The potential applications are exciting. Imagine a researcher being able to instantly query the entire Talmud for every instance where a specific Sage discusses a particular concept, or track the evolution of a legal term across different tractates.
Such tools could significantly accelerate research, aid in pedagogy by providing new ways to visualize Talmudic content, and enhance existing digital Talmud platforms with richer metadata and search capabilities.
Conclusion
The Talmud NLP Indexer represents an effort to bridge the gap between classical wisdom and modern technology.
By applying natural language processing techniques to the complexities of the Babylonian Talmud, we hope to create tools that assist scholars, students, and enthusiasts in navigating and understanding this foundational text in new ways.
While challenges remain, the potential to unlock deeper insights and facilitate novel forms of engagement with the Talmudic corpus makes this an exciting field of inquiry.
We welcome discussion and collaboration as this project progresses.
Appendix - Blog Archive and Tagging on GitHub Repo
As an aside, not directly related to the topic discussed in the main piece, I’ve backed up my entire blog (last 2.5 years of posts, 500+ posts) on my Github, repo here:
https://github.com/EzraBrand/blog-archive
Screenshots:
Index:
https://github.com/EzraBrand/blog-archive/blob/main/blog-archive/index.md
Screenshot of beginning (dark mode):
https://github.com/EzraBrand/blog-archive/blob/main/blog-archive/index.md#2025:
Scrolled down - year 2024:
https://github.com/EzraBrand/blog-archive/blob/main/blog-archive/index.md#2024:

Categories
https://github.com/EzraBrand/blog-archive/blob/main/blog-archive/categories.md
Screenshot, category ‘Biblical’:
https://github.com/EzraBrand/blog-archive/blob/main/blog-archive/categories.md#biblical

The Github repo for this project is here:
https://github.com/EzraBrand/talmud-nlp-indexer
For a technical overview of the project, see here:
https://github.com/EzraBrand/talmud-nlp-indexer/blob/main/STATUS.md
See my previous pieces on the ideas that I’ve developed, that are being brought together here:
Prospectus for a Named Entity Recognition (NER) System to Facilitate Talmud Research
Talmud Geographical Names (Toponyms) Extracted From Steinzaltz Translation
See also the paper here, from Adina Bruce, a student of Josh Waxman at Yeshiva University, from 2021, which discusses some of the technical aspects and challenges of a Talmud NER:
That paper focuses on rabbis’ names specifically.
It also discusses SpaCy, which is still today the main relevant Natural language processing (NLP) tool (earlier NERs may have used NLTK).
The paper also discusses Jastrow’s Talmud Dictionary and its abbreviations at relative length (see p. 19ff), a topic that’s relevant to my work as well, in the context of a script that I’ve built to modernize Jastrow’s entries and make them more easily readable for the modern reader, see my recent appendix on this, here, “Appendix - New Mini-tool / web app: ‘Jastrow Dictionary Abbreviation Modernizer’“.
On the size of the Talmud, in context, see my recent note in my piece “Beyond the Mystique” (cited in the next footnote).
Another highly relevant significant aspect of the Talmud, from a comparative context, is the massive amount of unique names mentioned; running into the thousands. This is something plan to return to, for now, see Bruce, cited in the previous footnote. On the topic of personal names in the Talmud in general in the Talmudic literature, see my overview in “From Abba to Zebedee: A Comprehensive Survey of Naming Conventions in the Mishnah, Talmud, and Late Antique Midrash“.
See my recent discussion as to what aspects of Talmud make it especially challenging to study, and what aspects less so, in my piece “Beyond the Mystique: Correcting Common Misconceptions About the Talmud, and Pathways to Accessibility“.
Based on the Hebrew Wiksource transcription of the traditional 19th century ed. Romm-Vilna.
Ordinal, cardinal, dates, etc.
Identification of numbers is a major aspect Spacy’s NLP processing, that also happens to be a major underrated aspect of the Talmud. The usage of number, enumeration, lists, and literary structure more broadly is a particularly fascinating element of the Talmudic literature, that I plan to discuss in the future.
For now, see my series of pieces at my Academia page, at section “Mishnah---Formatted“.
There, I collect a wide variety of examples of this kind of literary structure in the Mishnah, including that of enumeration:
For an overview of the general concept, see Chan Hee Song et. al., “Improving Neural Named Entity Recognition with Gazetteers” (2020).
And see below, in section “Gazetteers”, for links and screenshots of the actual gazetteers used in our project.
As a side note, this sentence-by-sentence segmentation serves as a non-arbitrary way to divide the text.
As opposed to the often arbitrary paragraph breaks in the Steinsaltz edition, as I’ve mentioned a number of times previously.
This is a topic I plan to return to as well.
See my short-term improvements listed in the ‘Status’ doc, here, step #0.
In general, my hope is that this will provide a base text and core functionality for the ChavrutAI web app.
See my mock-ups for how this would look in practice for the user, here: “Pt2 ChavrutAI Web App in Progress: Advancing the Vision of a More Accessible Talmud“.
See in this regard especially ibid. section “Mock-up of tab “Summaries & Key Terms”.
Wow, uncovering new layers of meaning with NLP is super impresive!