

Tag, You're It: A Review of Dicta's New Part-of-Speech Tagging Tool, and Comparing it with ChatGPT4
Wikipedia defines “Part-of-speech tagging” as follows:
“In corpus linguistics, part-of-speech tagging (POS tagging [..]), also called grammatical tagging, is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech, based on both its definition and its context [...]
Once performed by hand, POS tagging is now done in the context of computational linguistics, using algorithms which associate discrete terms, as well as hidden parts of speech, by a set of descriptive tags.”1
Dicta's 'Morph-Analysis’ tool provides powerful POS tagging. The 'Analytics' tool serves as a kind of search interface. (See the links below.)
This tool is quite powerful, and deserves to revolutionize quantitative study of Hebrew texts.
These are the fields in Dicta’s output that I believe are most useful, and that I checked using ChatGPT4:
‘word’
‘unvocalized_lex’ (=unvocalized lexeme)
‘POS’ (=part-of-speech)
‘fAramaic’
Some weaknesses and errors
However, a few weaknesses I found, in a quick testing of the tool on a Talmudic passsage (see full detail in the rest of this piece):
The tag 'PROPERNAME' is often absent in Dicta’s tagging, where it should be present. ChatGPT excels, particularly in tagging proper names like ששת, הונא, חייא, and אחא.
The data in Dicta’s 'fAramaic' field is fairly unreliable.
While ChatGPT4 adeptly tagged 18 words that Dicta struggled with (Docta labeled them as POS = 'NONSTANDARD'), it misinterpreted דאפסירא. Initially, ChatGPT also labeled a few words as 'Term/Phrase', which isn't quite accurate. However, upon further inquiry, ChatGPT rectified its tags appropriately.
Dicta links
ניתוח מורפולוגי -
https://morph-analysis.dicta.org.il/
דיקטה אנליטיקס -
https://analytics.dicta.org.il/
The Talmudic passage tested on
ChatGPT4 transcripts
Pt1 - queried ChatGPT4 to do parts of speech tagging on the passage
https://chat.openai.com/share/85a5fb81-06bf-4002-a6e8-fb7a4f52c0fa
pt2 - queried ChatGPT4 to find mistakes in First 100 rows of morph-analysis.dicta tagging export:
“I'm going to provide you with a table of parts of speech taggings of a hebrew/aramaic passage in babylonian talmud Kiddushin 27a. give me a list of corrections and improvements.”
https://chat.openai.com/share/b0785751-d15c-4d03-a390-113cd1423cc9
Dicta correct:
2 - למוד - VERB - tricky! Typically would be limud, meaning ‘study’. But here, it’s lamod, meaning ‘to measure’
5 - שאני - and aramaic = TRUE
ChatGPT4 correct:
1,3 - נתון and מושכר - PARTICIPLE - (meaning "given" and "rented") - see below, on ‘Participle’
6 - חוזר - VERB and not an adjective
7 - רב - TITULAR
8, 9 - חייא and הונא - PROPERNAME
11 - אידך - ADJECTIVE- and aramaic = TRUE
Both wrong:
4 - צבורים - PARTICIPLE , not VERB or NOUN- see below, on ‘Participle’
13 - אותה
ChatGPT4 made two ‘corrections’, where it in fact gave the same tag as Morph-analysis.dicta
Both missed:
אבין is PROPERNAME
Participle
Participle - Wikipedia > “Hebrew”:
Like Arabic, Hebrew has two types of participles (בינוני bênônî): an active participle (בינוני פועל bênônî pô'ēl) and a passive participle (בינוני פעול bênônî pā'ûl). These participles are inflected for gender and number.
In modern hebrew lingusitics, the qal passive participle is called:
קל סביל
or:
בינוני
Cf. the list of passive participle (בינוני פעול bênônî pā'ûl) at Hebrew Wiktionary, here: קטגוריה:קָטוּל (משקל) - ויקימילון
Appendix - technical analysis of Dictas tags
Tags used by Dicta, in order of usage, in a test of ~1200 words
NOUN
VERB
PREPOSITION
PUNCTUATION
CONJUNCTION
NUMERAL
INTERROGATIVE
NEGATION
ADJECTIVE
PRONOUN
PARTICIPLE
PROPERNAME
ADVERB
EXISTENTIAL
NONSTANDARD
TITULAR
QUANTIFIER
AT_PREP
MODAL
INTERJECTION
COPULA
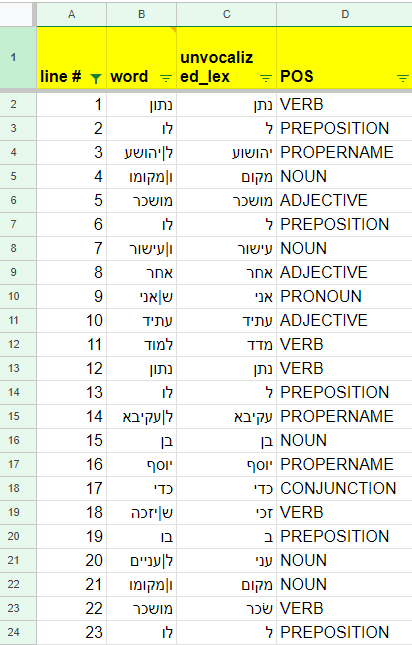
Screenshot of the beginning of table of Dicta’s results, in a Google Sheet
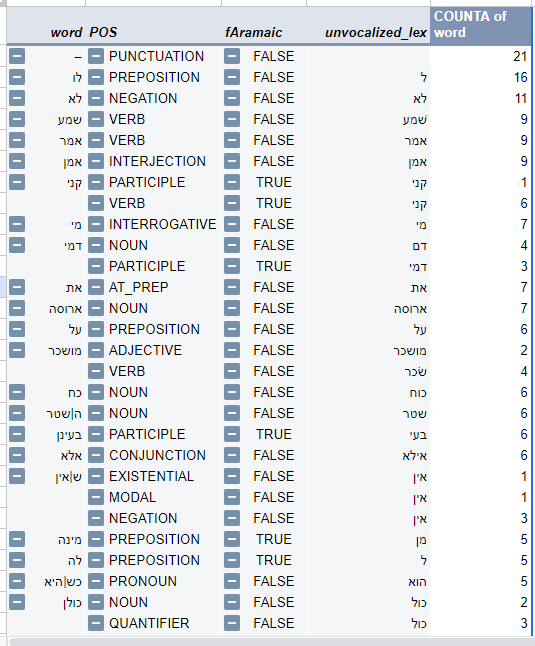
Screenshot of pivot table of results
As an aside, part of speech tagging has recently risen to prominence, as it's a major element of the revolution in workable large language model (LLM) training. For a good, recent, accessible introduction to linguistics, see the following series: Cambridge Introductions to Language and Linguistics.