

What is the largest page size in the Talmud, by word count? Estimating the upper bound using samples and code
The result: The longest page by word count, by far, was Sanhedrin 108a, at 771 words. Presumably, this is roughly the upper bound of the number of words on a talmudic page.
Before we begin, for those who understand modern Hebrew, I’d like to recommend this excellent podcast-style discussion with Prof. Yishai Rosen-zvi, on Midrash, part of an intro series on early Rabbinic works: https://youtu.be/7wpogx6vjFA
Previous pieces on word counts (revisions of previous blogposts, on my Academia.edu page, registration required):
And see my previous piece where I go into more detail on the technical aspect: “Quantifying the Talmud: A Technical Dive into Chapter Word Counts” (September 19, 2023).
As far as I’m aware, there is no publicly available discussion of what the longest page in the Talmud is.
Data Acquisition
The source for this analysis was the Hebrew-language Wikisource website, which is the main source for open-access, transcribed Jewish texts. (On this resource, see my “Guide to Online Resources for Scholarly Jewish Study and Research - 2023”, pp. 10-1 [Academia.edu, registration required]).
Previously, when I counted chapters, my script targeted the Hebrew Wikisource index page of chapters of the Talmud, for data collection (two pages, max 200 hyperlinks each):
קטגוריה:פרק בתלמוד הבבלי – ויקיטקסט
This time, after checking and testing a few different category and index pages, I concluded that it would be best to use the pages linked at the Hebrew Wikisource Table of Contents for Talmud Bavli. Each page linked is a table of contents of the tractate, split into paragraphs by chapter. Screenshot:

Here’s a screenshot of a page linked from there, from the tractate with the highest number of pages, Bava Batra (175 folios = 350 pages):

Final findings
Using the code I developed, I checked all pages in 6 tractates. The result: The longest page by word count, by far, was Sanhedrin 108a (Wikisource, Sefaria), at 771 words. Presumably, this is roughly the upper bound of the number of words on a talmudic page.1
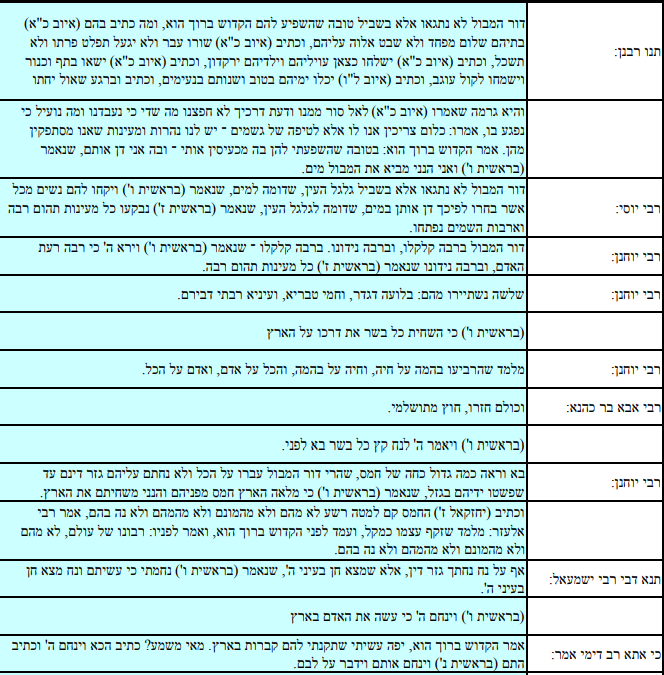
Screenshot of the page (at daf-yomi.com):

Compare this wall of text with the far more accessible formatting in Ohr Sameach’s Talmud Navigator, pp. 9-11, with the ~20 statements on the page clearly presented.



I’ll discuss some more of these types of pages in a future post.
Appendix - full code
Outline of the code:
Get URLs and page names
For each page:
Find the section containing the Talmud text
Count words in that section, excluding text in parentheses
Don’t count if page name starts with "בבלי” or "פרק":
Sort final table by 'Word Count' in descending order
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
from concurrent.futures import ThreadPoolExecutor
# Function to count words in a specific section of a webpage, excluding text in parentheses
def count_words_in_section(url_name):
name, url = url_name
if name.startswith("בבלי") or name.startswith("פרק"):
return name, url, 0
try:
response = requests.get(url, timeout=10)
soup = BeautifulSoup(response.content, 'html.parser')
# Find the section containing the Talmud text
talmud_section = soup.find("div", {"class": "gmara_text"})
if not talmud_section:
return name, url, 0
text_content = talmud_section.get_text()
# Remove text within parentheses
cleaned_text = re.sub(r'\(.*?\)', '', text_content)
word_count = len(cleaned_text.split())
except Exception as e:
# Handle exceptions, such as connection errors
print(f"Error processing {url}: {e}")
word_count = 0
return name, url, word_count
# URL of the webpage containing the list of URLs
list_url = "https://he.wikisource.org/wiki/%D7%91%D7%91%D7%9C%D7%99_%D7%91%D7%91%D7%90_%D7%9E%D7%A6%D7%99%D7%A2%D7%90"
# Get URLs and page names
response = requests.get(list_url)
soup = BeautifulSoup(response.content, 'html.parser')
urls_and_names = [(a.text, "https://he.wikisource.org" + a['href']) for a in soup.find_all('a', href=True) if a['href'].startswith("/")][:400]
# Use ThreadPoolExecutor to process URLs in parallel
with ThreadPoolExecutor(max_workers=25) as executor:
results = list(executor.map(count_words_in_section, urls_and_names))
# Convert to DataFrame
df = pd.DataFrame(results, columns=['Page Name', 'URL', 'Word Count'])
# Sort DataFrame by 'Word Count' in descending order
df_sorted = df.sort_values(by='Word Count', ascending=False)
# Convert sorted DataFrame to Markdown
print(df_sorted.to_markdown(index=False))
For comparison, I asked ChatGPT4 for a general estimate for standard word count on a page of a scholarly text, and it estimated that “single-spaced pages with the same font and margins would contain roughly 500 to 600 words.“ Those pages always have standard punctuation, of course.