

Pt1 ChavrutAI Web App in Progress: Advancing the Vision of a More Accessible Talmud
This is the first part of a two-part series. Part 1 will focus on the detailed vision, and Inspiration & Models, while Part 2 will focus on prototypes and mock-ups. The outline for the series is below.1
ChavrutAI is a work-in-progress open-access web app aimed at making the Talmud more accessible, explorable, and navigable for contemporary audiences—scholars, students, and the curious public alike.
Outline
Rationale
The Vision
Features (Planned, Roadmap)
Textual Processing, Analysis & Tools
Side-by-Side Bilingual View
URL Structure & Navigation
Integration with Existing Resources
Contextual Metadata & Wikification
Semantic Highlighting
ChavrutaAI bot - personalized LLM-assistance
Additional possible longer time-horizon ideas, esp. Customization
Academic/ scientific / scholarly
Inspiration & Models
Work done by Prof. Menahem Katz
Perseus Project
Digital Dante (Columbia University)
Current Status (prototypes / pre-alpha versions)
Fetching Talmud text (Hebrew and English)
Custom Instruction, for processing text, and for AI / LLM, for querying a general LLM model re Talmud questions
MVP (Minimal Viable Product Specification) - Upcoming Beta Version
Text Source Integration
Primary View (inspired by Sefaria + Perseus)
Frontend
Backend
Initial Development Focus
Mock-up of the Proposed Interface of the web app - with focus on the UX/UI and Aesthetics
Mock-up of main tab (“Text & Translation”)
Mock-up of tab “Summaries & Key Terms”, top (in tablet/mobile view)
Mock-up of tab “Summaries & Key Terms”, scrolled down (in tablet/mobile view)
Mock-up of tab “Broader Analysis”, top (on tablet/mobile)
Mock-up of tab “Broader Analysis”, scrolled down to the bottom (on tablet/mobile)
Rationale
As I outlined almost two years ago in my post at the Seforim Blog2 and developed extensively on this blog, the traditional and highly conservative “tzurat hadaf” of the Talmud imposes major constraints—highly arbitrary pagination, visually dense, extremely minimal formatting, and layered commentary—that can be easily and massively transcended in digital editions.
This project aims to reflect the structure of Talmudic sugyot more faithfully, aided throughout by contemporary tools.
Ultimately, this is not just about access, but about intelligent access—making the Talmud readable and explorable by sensitivity to its literary, legal, and narrative structures in ways that reflect contemporary research and technological capabilities.
The Vision
Building upon existing monumental resources--especially Sefaria--the goal is to extend (or—in contemporary tech parlance—provide a “wrapper” for) the capabilities of current platforms and to customize it for Talmud reading and study, by drawing inspiration from the best practices in the broader field of digital humanities and user experience.
This web app will present the Talmud in a fully digitized format offering clean, semantic HTML. It will incorporate both the original Hebrew/Aramaic text and the major open-access English translation/interpretation (Steinsaltz edition), with rich typographic formatting, side-by-side display, and responsive design.
Features (Planned, Roadmap)
Textual Processing, Analysis & Tools
Each section broken further into less arbitrary sections, based on punctuation,3 as well as other processing of the English translation/interpretation to make it more accessible, readable, modern, and accurate.4
Bible verses quoted: highlight and make accessible/add punctuation5
User can highlight to pull Jastrow dictionary entries.6 The dictionary definition pane will also display and hyperlink to the Hebrew Wiktionary definition.
Named Entity Recognition (NER) for rabbis, places, and other technical terms, with links to Wikipedia entries.7 Visually indicate recognized names in the text.8
Side-by-Side Bilingual View
Hebrew and English aligned horizontally9
Rich text formatting preserving bold and italics10
Optimized dynamic layout, updates dynamically based on device/window aspect ratio (desktop/tablet/mobile), with customization options11
URL Structure & Navigation
Unique URL for every daf/amud/section (e.g., Sanhedrin.90a.2), as well as for ranges of sections, for deep linking, mirroring Sefaria
Topic-based navigation and section headers12
Integration with Existing Resources
Link back to Sefaria page for additional resources, commentaries, and cross-references
Modular design to eventually support Mishna, then Bible
Contextual Metadata & Wikification
Topic labeling for sections and pages13
"Wikification" of key concepts with links to relevant reference materials: Keyword/concept tagging per page with links to Hebrew and English Wikipedia entries.14 Query the Wikipedia API to fetch the relevant pages.15
Semantic Highlighting
Identify and color-code halakhic vs. aggadic content per sugya.16
Display section summaries, summary tables, and labels (e.g. “Story about Elijah,” “Law of Apostates”), aided by queries to an LLM
ChavrutaAI bot - personalized LLM-assistance
An on-page chatbot will provide a wrapper for questions to an aligned LLM (for alignment/custom instructions for a general LLM, see the upcoming Part 2), for customized assistance for the user/”learner”
Labels, overviews/background info/intros, summary tables, and various other visualizations, aided by LLMs.17
Additional possible longer time-horizon ideas, esp. Customization
Allowing extensive customization in fonts (both Hebrew and English) and other display
More granular customization of preferred level of explanation
Customization of terminology in translation/interpretation (terminology used, amount/type of Hebrew-to-English, type and amount of transliteration/romanization
Audio and video features.18
Academic/ scientific / scholarly
Providing an interface for advanced search.19
Manuscript and other variants (= גירסאות, שינויי נוסח): Moving past the traditional edition (the 19th century ed. Romm-Vilna), and incorporating manuscript and other historical attestations
Source criticism (= רבדים): separating by historical layers (tannaitic; named statements; Stam)
Even more speculative is AI-generated scholarship (חידושים).20
Inspiration & Models
Work done by Prof. Menahem Katz
The work done by Prof. Menahem Katz.21
Screenshot of sample of ibid., Yerushalmi Yevamot
https://www.talmudyerushalmi.com/talmud/yevamot/001/001
(Note, for all screenshots: where the page is a web app/website, I narrowed the view, to be closer to tablet/mobile view, to be able to show it more easily on a standard aspect ratio Substack reader)

Screenshot of sample of ibid., Bavli Yevamot, Table of Contents (p. 2):

Screenshot of Yerushalmi sugya mapping
https://assets.talmudyerushalmi.com/documents/research/sugyot_map_yevamot_01.pdf

Perseus Project
While the Jewish digital text space contains some major, relatively well-developed and modern resources (esp. Sefaria, Hebrew Wikisource, Al-HaTorah), this project looks outside that ecosystem for additional inspiration from the wider digital humanities field:
Scaife Viewer (Perseus Project)
Best-in-class model for bilingual Greek-English reading
Hover definitions, word frequency lists, and deep metadata integration
Screenshot of sample page , in the newer interface
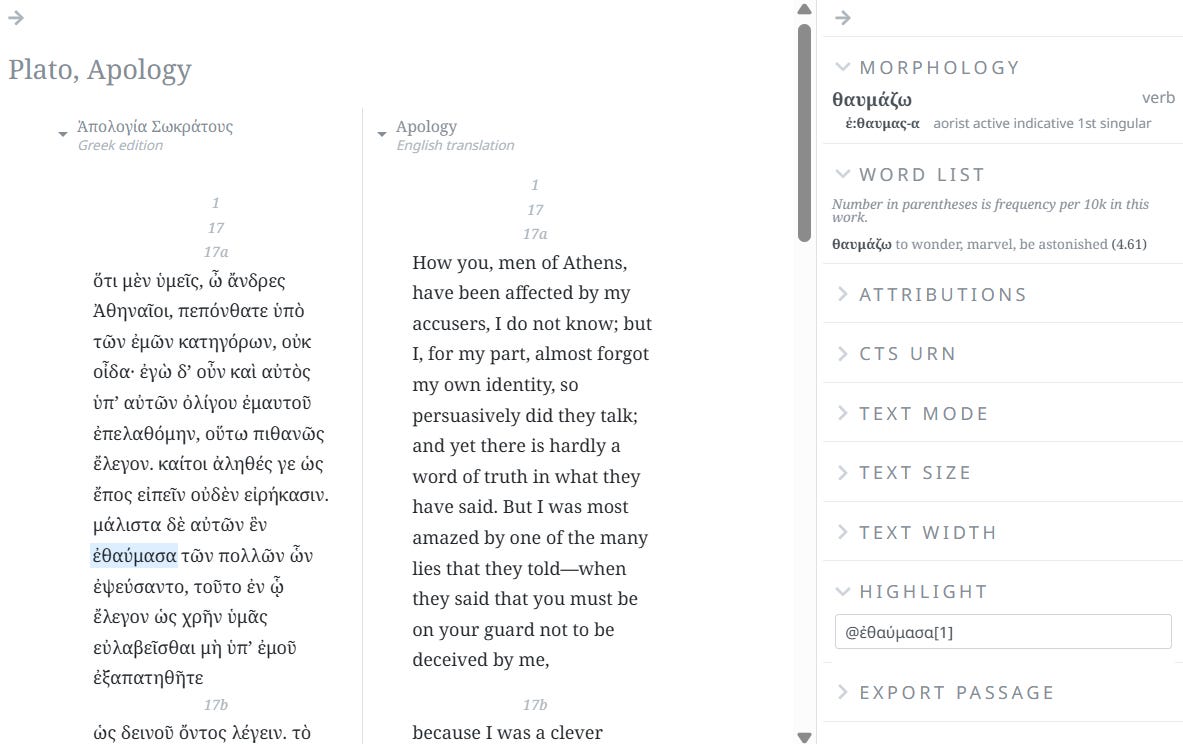
Screenshot from Perseus’s older interface, illustrating their notable navigation system,
visualized using horizontal bars (chunked by chapter (vs. section). Tabs to the right clicked “hide”:
Note: I erased from the screenshot a lot of the surrounding navigation links and meta-data that appear on that page, as it’s mostly irrelevant for our purposes here)

Screenshot of ibid., showing “Notes” opened (“focused”):

Screenshot showing opened-up “[original] Greek” and “Places (automatically extracted)”
Digital Dante (Columbia University)
Digital Dante (Columbia University)
Screenshot of sample page, tab “Text & Translations”
( https://digitaldante.columbia.edu/dante/divine-comedy/purgatorio/purgatorio-6/ > tab “Text & Translations”):

Screenshot of sample page,
Ibid., tab “Commento Baroliniano” (summary/overview of the passage under discussion):

Screenshot of Table of contents:
https://digitaldante.columbia.edu/commento-baroliniano/

See my previous piece on the topic here: Proposal for ChavrutAI: An AI Chavruta for Studying Talmud.
“From Print to Pixel: Digital Editions of the Talmud Bavli” (June 5, 2023). Reposted at my Academia page here.
The script for this has already been developed and the web app is live, see Part 2.
Modernization of style, more accurate / precise translation, changing spelled-out words to Arabic numerals, etc
I.e. modern punctuation—not nikud—which, in the Hebrew/Aramaic original formatting of the Sefaria edition of the Talmud, is entirely missing from Bible verses; unlike in the rest of the original Hebrew/Aramaic text, and in the English translation/interpretation.
As currently exists for Sefaria; use JavaScript to detect text selection within the Hebrew/Aramaic text panes; with Jastrow text modernized via special Jastrow processing script - have Python script in Google Colab notebook for this.
See my piece on this at my Academia page.
Much of the initial work on gazetteers--lists of known names--has already been done, see my extensive, maximalist list of personal names extracted from the Talmud (3000+ unique names).
E.g., subtle underline, as already done by Sefaria.
However, Sefaria’s implementation leaves much to be desired.
A major aspect that can be improved upon is the number of entities recognized, as well as the information provided for each recognized entity.
For all of this, as well as definitions, in previous, and “Wikification”, see next, a customized robust semantic identification and disambiguation scripting solution will be required, to identify the correct semantic sense.
As offered by Sefaria, Scaife, and Digital Dante, see below. However, the former two have blocks of text; it's desirable to have further intelligent splitting into “paragraphs” by clause, at least as an option; see earlier.
Bolding used by ed. Steinsaltz to differentiate between translation vs. gloss/interpretation; while italics indicates a transliteration, as is standard.
Sefaria has customization options, but there's much that can be improved upon, with current tools.
As well as breadcrumbs. See my mock-up in Part 2.
Compare Scaife’s navigation UI, using horizontal bars, see below.
Important models for splitting into named sugyot are Prof. Menachem Katz’s “Menachem’s Notebooks” (מחברות מנחמיות - see citation in a later note) and the volumes of the Talmud HaIgud, under the editorship of Prof. Shamma Friedman. (On this project, see my overview in my “Guide” (citation in a later note).
It should be pointed out that the ed. Steinsaltz at Sefaria does have some form of splitting into sugyot, using the section symbol (‘§’).
However, I don’t believe that that splitting is especially useful, especially since it’s given with no title for the sugya, and it overall still seems fairly arbitrary.
In general, the topic of the “stream of consciousness” /associative style of the Bavli is a major one, that I hope to discuss further.
For now, see my recent piece where I explored this somewhat via a case study: Selection of Men for Intercalation of the Hebrew Calendar and Stories of Emotional Self-Sacrifice to Protect Others From Embarrassment (Sanhedrin 10b-11a), see there “Appendix 3 - Making Talmudic Aggadah More Accessible with AI: A Case Study“.
Compare Scaife's “Word List” box, see screenshots below.
Caching the major ones; see my list at my Academia page of top 100 relevant entries.
Currently can do this via proxy of word density per page; I’ll demonstrate this in an upcoming piece.
Of course, the issue of hallucinations is a serious one (currently, and for the foreseeable future), so a prominent disclaimer will be in order.
I.e. shiurim , via text-to-speech and text-to-video.
See my notes on this in my piece “Pixel”, as well as various other pieces at my Academia page.
As an aside, one of the major challenges is getting non-English words to be pronounced correctly.
Compare Dicta and Sefaria search--while somewhat advanced, the options are still relatively limited, compared with what can be done relatively simply with regex.
Compare Scaife’s search, which is fairly advanced, while still having a straightforward UI.
Other Ideas for search: by tradent/speaker/Tanna/Amora, linguistic search aware of Hebrew/Aramaic roots and morphology, by topic or halachic vs. aggadic.
Compare Avi Schmidman’s work on programmatic disambiguation and spell check for rabbinic Hebrew, with machine learning (BERL), and the recent work of Satlow et. al. extending that to comparing word senses between Talmud Bavli and Yerushalmi.
This doesn’t currently seem to be relevant.
Compare discussions on reasoning.
However there are those claiming that Chatgpt4’s recently release o3 model may be capable of true reasoning.
This includes a number of projects of Katz’s, that he’s worked on together with Hillel Gershuni:
The monumental “Hachi Garsinan” website, which gathers all the major versions of the Talmud Bavli, and has already been a fundamental tool in this field for many years. See my overview of this resource in my “Guide to Online Resources for Scholarly Jewish Study and Research” (at my Academia page), p. 18.
Katz’s formatting of Talmud Bavli. See the links listed in my “Guide”, ibid., p. 15. On that, see my short review in my piece “Pixel” (cited earlier), as well as pieces a while ago where I made initial attempts to programmatically emulate it.
Katz’s ongoing monumental project on Talmud Yerushalmi (I plan on reviewing that project soon).
https://www.talmudyerushalmi.com/
See some of this other relevant previous work here, relating to Talmud and digital humanities:
https://www.talmudyerushalmi.com/resources
Especially see a combined splitting into sugyot of Bavli tractate Yevamot:
https://assets.talmudyerushalmi.com/documents/research/bavli_yevamot.pdf
Bavli tractate Ketubot:
https://assets.talmudyerushalmi.com/documents/research/bavli_ketubbot.pdf
See also his work on Tosefta tractate Yevamot:
https://assets.talmudyerushalmi.com/documents/research/tosefta_yevamot.pdf