

Talmud Text Segmentation: Toward a Semantically-Aware Hebrew-English Phrasal Alignment Pipeline at ChavrutAI
I’ve started working on a pipeline to segment Talmud text via an LLM pipeline, for ChavrutAI.1 The core idea is simple: break the text into phrase-sized chunks and show Hebrew and English side by side, aligned by meaning.2
This post explains what I’m building and why.
Outline
Intro
The Problem with Dense Talmud Text
What I Wanted Instead
How It Currently Works
Proposal (High Level)
Segment Length and Dialogue
Initial Focus: Narrative Passages
What’s Next
Future Work
Appendix - Technical
Data Source
Pre-processing
LLM Segmentation Approach
Validation
Fallback: Rules-Based Segmentation
Segment Alignment
Caching
The Problem with Dense Talmud Text
Open any page of Talmud and you’ll see walls of text. The Aramaic original is terse: sometimes a few words carry the weight of an entire argument. The ed. Steinsaltz English translation (via Sefaria) adds explanatory material, which helps comprehension but makes the text longer and harder to navigate.
Here’s what a typical section looks like on Sefaria (where it has no special processing), screenshot of https://www.sefaria.org.il/Sukkah.52a.10-11:3

That’s one paragraph. It contains a statement, a narrative setup, quoted dialogue, internal thought, and a decision to act. Reading it as a block obscures the structure.
The Talmud has a distinctive literary style. It’s formulaic and laconic. It uses parallelism extensively. Arguments often follow patterns: “Rabbi X says A because of proof B; Rabbi Y says C because of proof D.”
When you display the text as a dense block, you lose the structure. When you break it into aligned phrases, the structure becomes visible.
This is also valuable for aggadic (narrative) passages. Stories and passages have clear dramatic beats. Phrase-level display makes those beats apparent.
What I Wanted Instead
I wanted to display the same text like this:
Hebrew:
אמר אביי: ובתלמידי חכמים יותר מכולם.
כי הא דאביי שמעיה לההוא גברא דקאמר לההיא אתתא:
נקדים וניזיל באורחא.
אמר: איזיל אפרשינהו מאיסורא.
English:
Abaye said: And it provokes Torah scholars more than everyone else.
It is like this incident, as Abaye once heard a certain man say to a certain woman:
Let us rise early and go on the road.
Upon hearing this, Abaye said to himself: I will go and accompany them and prevent them from violating the prohibition.
Each line is a phrase. The Hebrew and English align by meaning. You can see the structure: statement, narrative frame, quoted speech, response.
This is how I format Talmud passages in my blog posts. I do it by hand, which takes time. I wanted to automate it.
How It Currently Works
The text comes from Sefaria’s API. Each Talmud page is divided into 10-20 sections. I’m working on segmentation within each section, not across the whole page.
The current approach uses simple rules: split on punctuation like periods, colons, and semicolons.4
Ed. Steinsaltz English translation has semantic formatting baked in.
Bold text is the direct translation of the Hebrew/Aramaic
Regular text is the Steinsaltz edition’s running commentary
Italics are transliterations (Hebrew terms in English letters) or technical terms
This formatting is a signal. The bold portions are what should align closely with the Hebrew. The non-bold portions are explanatory glue. I preserve this formatting in the output.
Here’s that same section at ChavrutAI, currently (https://chavrutai.com/talmud/sukkah/52a#section-11):
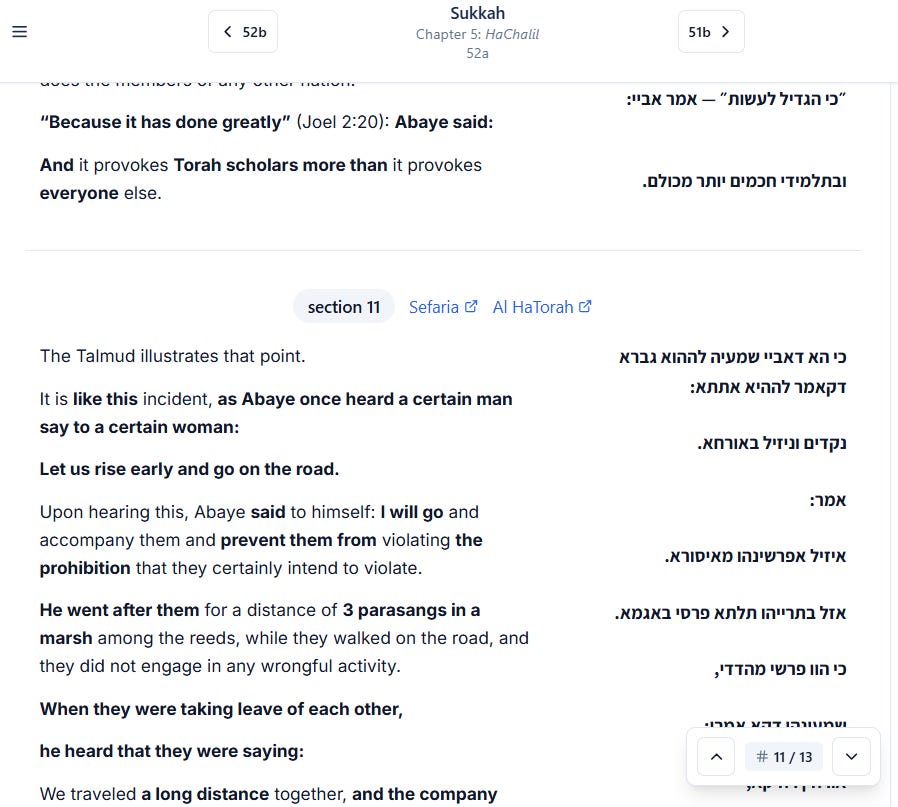
Plan (High Level)
This works okay but has problems. It splits too aggressively sometimes, and it doesn’t understand meaning. It can’t tell when a colon introduces a long quote (split after the colon) versus a short statement (keep it together).
I’m planning on adding an LLM layer to make smarter decisions. The language model sees both the Hebrew and English text. It identifies where phrases should break. It outputs boundary markers, and I split the text on those markers.
The key constraint: the LLM doesn’t change the text. It only marks where to split. After processing, I verify that concatenating all the segments exactly reproduces the original. If anything is different, I reject the result and fall back to the simple rules.
Segment Length and Dialogue
How long should a segment be? Based on my blog posts, most phrases are 5-15 words. Longer than 20 words usually means I should look for a natural break.
Dialogue is interesting. Whether to separate “He said:” from what follows depends on context.
If the statement is short, keep it together:
He said: I will go with you.
If the statement is long (multiple segments), separate:
He said:
I will go with you.
And I will protect you from harm.
For back-and-forth exchanges, keeping attribution with the statement preserves the rhythm:
He said: X
She said: Y
He said: Z
Understanding the literary structure matters. The segmentation should ideally reflect how the text is structured, not just where punctuation happens to fall.
Initial Focus: Narrative Passages
I’m starting with aggadic sugyot; the narrative and homiletical passages rather than the legal discussions.
Once I have the approach working well on narratives, I’ll extend it to halakhic (legal) discussions, which have their own structural patterns.
What’s Next
I’m building a prototype. The pieces are:
Fetch text from Sefaria (already working)
Send to LLM with segmentation prompt
Validate output integrity
Display aligned Hebrew/English phrases
I’ll share results as I have them. The goal is a tool that makes Talmud text more accessible, as well as revealing the underlying literary structure.
Future Work
Semantic role tagging (narrative, dialogue, proof-text, etc.)
Parallel structure detection for bullet-point formatting
Pre-computation for commonly-accessed aggadic passages
Appendix - Technical
This appendix describes tentative implementation details. The current spec doc can be found at my Github, as part of the ChavrutAI repo “Issues”, in the latest comment to issue #4:
Data Source
Text comes from Sefaria’s public API:
GET https://www.sefaria.org/api/texts/{ref}
Response structure:
{
“ref”: “Sukkah 52a”,
“text”: [”section 0”, “section 1”, ...], // English, 10-20 sections per page
“he”: [”section 0”, “section 1”, ...] // Hebrew/Aramaic
}
English sections contain HTML: <b> for translation, <i> for transliteration, plain text for commentary. Hebrew sections are plain text with optional nikud (vowel points).
Pre-processing
Hebrew: Remove nikud using regex. Keep punctuation. English: Keep as-is, including HTML tags.
LLM Segmentation Approach
Send both Hebrew and English to the LLM in a single request. The prompt instructs:
Insert | boundary markers at phrase breaks
Number segments
[1], [2],etc. to ensure alignmentDo not modify any text—only add markers
Example output:
Hebrew: [1] אמר אביי: | [2] ובתלמידי חכמים יותר מכולם.
English: [1] <b>Abaye said:</b> And it provokes... | [2] It is <b>like this</b>...
Validation
After receiving LLM output:
Split on
|markersStrip
[n]labelsConcatenate segments (whitespace-normalized)
Compare to original input
If mismatch: reject, use rules-based fallback
Checksum comparison:
const normalize = s => s.replace(/\s+/g, ‘’);
const valid = normalize(original) === normalize(segments.join(’‘));
Fallback: Rules-Based Segmentation
Current implementation in shared/text-processing.ts:
Split on
., :, ;, ,(with exceptions for abbreviations)Handle “son of” patterns, ellipses, quoted text
Deterministic, no API cost
Segment Alignment
Segments are 1:1 between Hebrew and English. The [n] numbering ensures correspondence. No 1:many or many:1 mappings; segment counts must match.
Caching
Plan to cache segmentation results per tractate/page/section. On first request, compute and store. On subsequent requests, serve from cache. Manual corrections can override cached values.
As an aside, I’ve continued to make other improvements there, see the changelog page:
February 2026
Text Processing Improvements
Hebrew text no longer splits after quotation marks (״), keeping quoted words inline
English text now correctly splits after semicolon + quote clusters (e.g., ];” stays together)
Added term mappings: “Sages” → “rabbis”, “our Lord” → “our God”
Added ordinal time expressions: “the first/second/third/fifth/tenth [unit]” → “the 1st/2nd/3rd/5th/10th [unit]” for year, month, day, week, hour, watch
Added “the Xth of the month” pattern (e.g., “the fifth of the month” → “the 5th of the month”)
Added number conversion: “three hundred and fifty four” → “354”
Added fraction: “thirteen and a third” → “13⅓”
Fixed ambiguous fraction/ordinal mappings: standalone “third”, “fifth”, and “tenth” no longer auto-convert (context-dependent)
Fixed kav measurements: “an eighth-kav” → “a 1/8th-kav”, “one-thirty-second of a kav” → “1/32nd-kav”
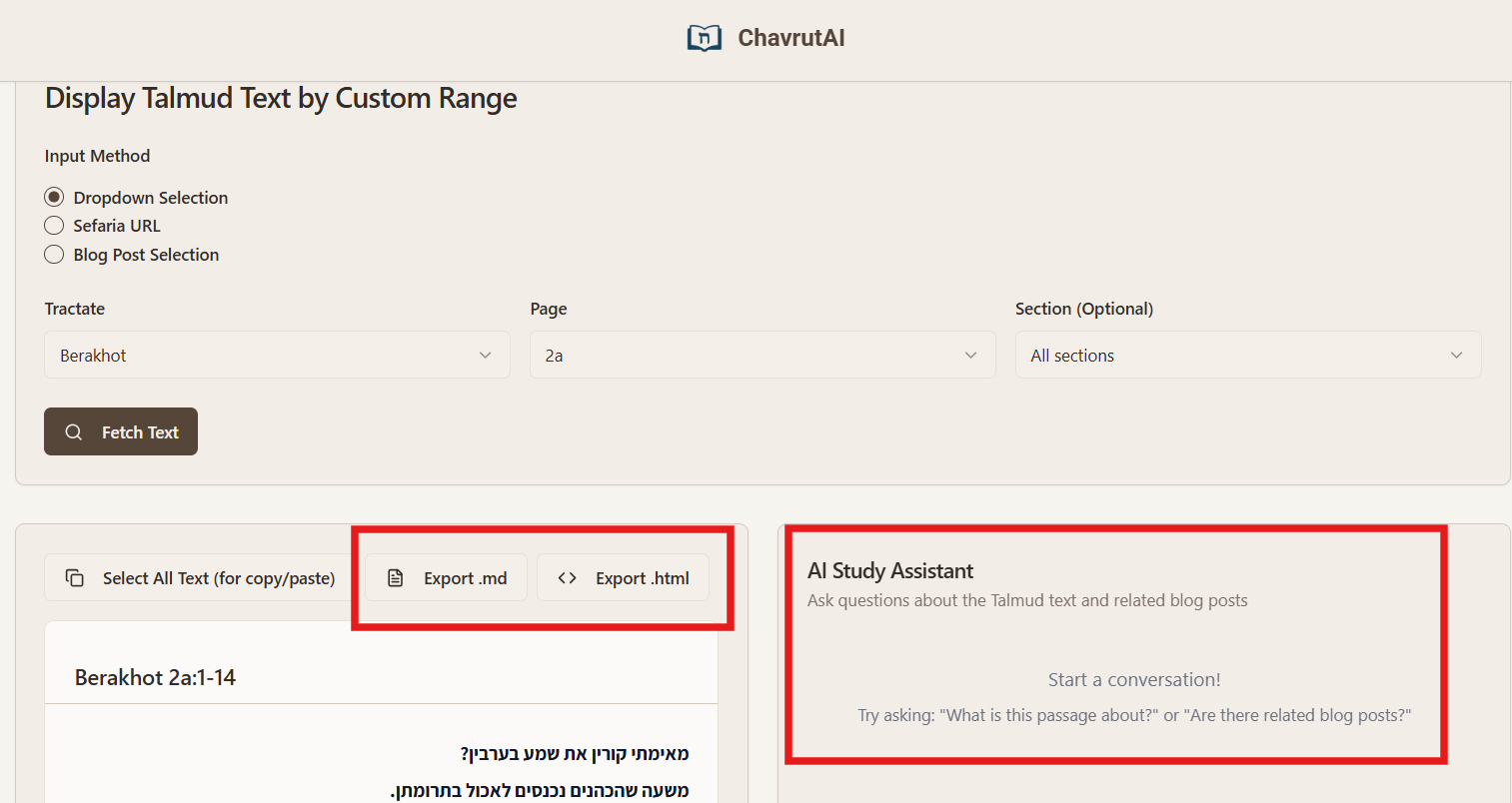
Sugya Viewer Export Options
Added export buttons for Markdown (.md) and HTML (.html) formats
HTML export retains rich formatting (bold, italics, RTL direction)
Markdown export preserves Hebrew text as bold for readability
Useful for uploading text to chatbot assistants that don’t retain formatting from copy/paste
See the “Sugya Viewer Export Options” at the sugya viewer page, with the “AI Study Assistant” on the side; I highlighted the screenshot with red boxes:
I also added additional FAQs, at the “About” page:
Compare Wikipedia, “Parallel text”:
A parallel text is a text placed alongside its translation or translations.
Parallel text alignment is the identification of the corresponding sentences in both halves of the parallel text […]
Large collections of parallel texts are called parallel corpora (see text corpus).
Alignments of parallel corpora at sentence level are prerequisite for many areas of linguistic research.
During translation, sentences can be split, merged, deleted, inserted or reordered by the translator. This makes alignment a non-trivial task.
Note that I set it in side-by-side view, as opposed to stacked Hebrew-then-English, which is the default.
Compare my previous discussion in “ChavrutAI’s Talmud Translation Processing Approach” (Dec 29, 2025).